A real world use case with Elixir Recursion
by Atul Bhosale,
Recently, I was working on writing a background worker using Elixir for one of our clients. There was a requirement to update records in a database table & also update those many records in another table. This post is about how I used Recursion to solve this use case.
I am working on an application where there are orders for each account. The background worker will search all orders which are pending & mark them completed & update those related accounts.
I searched for something similar to find_in_batches from Rails in Elixir and found this discussion.
I came across Ecto.Repo.stream/2 to iterate through each Order, update its status & then update the accounts related to those orders. It can be done as follows:
defmodule BalanceUpdateWorker do
alias Bank.Order
alias Bank.Account
alias Bank.Repo
import Ecto.Query
@pending 0
@completed 1
def perform do
Repo.transaction(fn ->
Repo.stream(orders_query())
|> Enum.each(fn order ->
{:ok, updated_order} = update_order(order)
{:ok, _} = update_account(updated_order)
end)
end)
end
defp orders_query() do
from(order in Order,
where: order.status == ^@pending
)
end
defp update_order(order) do
order
|> Order.changeset(%{status: @completed})
|> Repo.update()
end
defp update_account(order) do
account = Repo.get_by(Account, user_id: order.user_id)
account
|> Account.changeset(%{amount: Decimal.add(account.amount, order.amount)})
|> Repo.update()
end
end
However, there is a problem with the above approach. When the time taken to update the records exceeds the timeout, Ecto will raise a timeout error as follows:
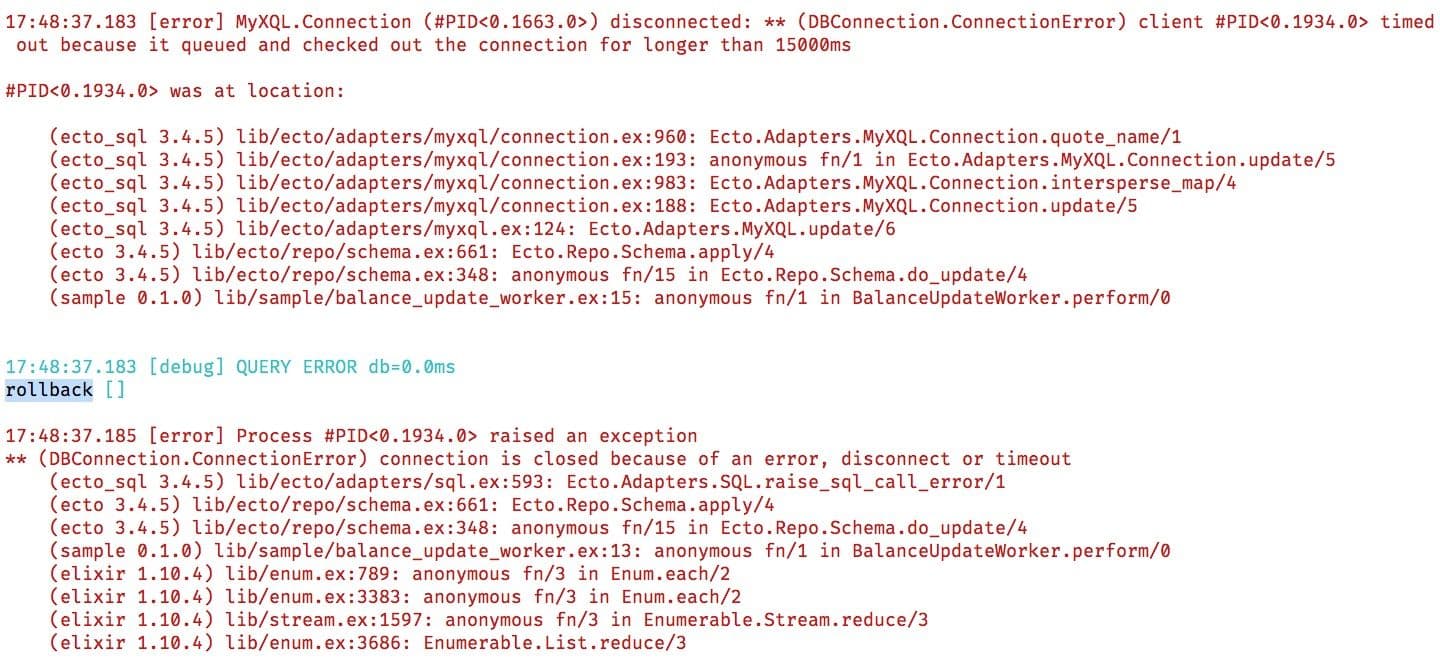
Also, all the record updates are rolled back.
In Repo.stream/2 the SQL adapters can only enumerate a stream inside a
transaction.
I realized that instead of having all records wrapped inside one database transaction, it's better to have a database transaction for each record update which will solve the database timeout problem.
In the new approach without Repo.stream/2, I will have to handle
find_in_batches by myself i.e. by iterating over a batch of records & then
proceeding to the next batch. This is a use-case of
recursion.
Using recursion, I can have a method that will call itself multiple times as long as the number of records yet to be processed is more than the batch size.
First, we need to know how many records are pending, then pass that count to a method that will process that batch of records & then calls itself again.
@batch_size 500
def perform do
remaining_records_count()
|> iterate_multiple_times()
end
defp remaining_records_count do
orders_query()
|> Repo.aggregate(:count)
end
defp iterate_multiple_times(count) when count <= @batch_size,
do: make_account_balance_available()
defp iterate_multiple_times(_count) do
make_account_balance_available()
remaining_records_count()
|> iterate_multiple_times()
end
defp orders_query_with_limit do
from(order in Order,
where: order.status == ^@pending,
limit: ^@batch_size
)
end
defp make_account_balance_available do
orders_query_with_limit()
|> Repo.all()
|> Enum.each(fn order ->
{:ok, updated_order} = update_order(order)
{:ok, _} = update_account(updated_order)
end)
end
In the above refactoring, the perform/0, finds out the count of records to be
updated & passes it to the iterate_multiple_times/1 recursion function.
If the count is above 500 it will process that batch of records & then count
remaining records & call itself and so on.
The updated code runs successfully.